
Introduction
In the rapidly evolving landscape of artificial intelligence (AI), staying at the forefront means constantly experimenting, learning, and innovating. For businesses, the speed at which we can use prototyping and test AI solutions directly impacts our ability to adapt, make informed decisions, and stay competitive.
At Origo, we believe that the power of AI should be harnessed not just to optimize but to revolutionize how businesses operate. Our mission is to help companies integrate AI seamlessly into their operations, empowering staff and driving both efficiency and revenue growth. However, one needs the right tools and platforms to experiment and prototype swiftly to achieve this.
One of our recent explorations led us to interact with Large Language Models (LLMs), particularly open-source ones. These models have garnered significant attention in the AI community for their ability to understand and generate human-like text, offering vast potential for various applications.
In this blog post, we’ll walk you through our journey of experimenting with some of the most portable and friendly open-source LLMs available. Leveraging platforms like Hugging Face, we were able to rapidly prototype and compare outputs from different models, gaining insights into their capabilities and potential applications for businesses. Whether you’re an AI enthusiast, a business leader looking to harness the power of AI, or just curious about the latest in the AI world, we invite you to join us on this exciting exploration.
The Importance of Fast Prototyping in AI
In the dynamic world of technology and innovation, speed is often the differentiator between being a pioneer and a follower. Nowhere is this truer than in the realm of Artificial Intelligence (AI). Here, fast prototyping emerges not as a luxury but as a necessity. But what exactly is fast prototyping, and why is it so pivotal?
Fast prototyping refers to rapidly creating a model or solution to test its feasibility, usability, and effectiveness. AI is about quickly building and deploying models to see how they perform in real-world scenarios. Let’s break down its importance:
- Quickly Testing Ideas: AI is about experimentation. With fast prototyping, companies can quickly test out hypotheses or ideas, assess their viability, and iterate based on feedback. Instead of spending months on a model only to discover flaws, prototyping can highlight these in days or even hours.
- Saving Time and Resources: Traditional model development can be resource-intensive, both in terms of time and finances. Fast prototyping allows businesses to identify the most promising models early, directing resources more efficiently.
- Accelerating AI Deployment: In today’s competitive landscape, businesses can’t afford to wait. Fast prototyping accelerates the timeline from ideation to deployment, enabling companies to leverage AI benefits sooner.
- Real-world Impact: Consider the healthcare industry, where AI models are being used to predict patient outcomes. With fast prototyping, a hospital could quickly test various models to determine which one best indicates patient needs, potentially saving lives. Similarly, in finance, prototyping could swiftly identify the best model for predicting stock market trends, providing a competitive edge.
The Advantages of Open-Source Language Models
The democratization of AI has been significantly propelled by the availability of open-source tools and models. Among these, Large Language Models (LLMs) like GPT-3 have captured the imagination of the AI community and beyond. But they’re closed, and we don’t have enough information about how they were constructed and how the data was managed. Thus, it’s essential to have open models that can be clearly reviewed by scientists, programmers, regulators, and people in general.
- Promotion of Innovation and Accessibility: Open-source models are available for anyone to use, modify, and improve. This fosters a culture of collective innovation, where a diverse group of developers and researchers contribute, leading to more robust and versatile models. Moreover, they level the playing field, allowing even those without vast resources to tap into state-of-the-art AI.
- Unparalleled Flexibility: Open-source LLMs offer incredible flexibility. They can be run locally on a machine, allowing for real-time, offline applications. They can be fine-tuned on proprietary data, tailoring them to specific business needs. Or, if preferred, they can be deployed on the cloud, ensuring scalability and cost-effectiveness.
- Democratization of AI: Open-source models are a significant step towards AI for all. They ensure that AI benefits are not restricted to those with deep pockets but are accessible to startups, independent researchers, and even hobbyists. This widespread accessibility ensures diverse applications and innovations from various sectors and regions.
Open-source LLMs are not just tools; they represent a shift in how we approach AI. They champion a more inclusive, innovative, and efficient way of leveraging AI’s immense potential, ensuring its benefits permeate every sector and touch every individual.
An Introduction to Hugging Face
Hugging Face Spaces is a platform that allows you to host your machine-learning models and create interactive web applications for them.
Here’s a brief rundown of the process of creating a new Space:
- Step 1: Sign up for an account.- To start, you’ll need to create a Hugging Face account. Head over to the Hugging Face website and sign up. You can create an account using your GitHub account or your email address.
- Step 2: Navigate to Spaces.- Once logged in, click on your profile picture in the top right corner, and from the dropdown menu, select “Spaces.
- Step 3: Create a new Space.- On the Spaces page, click the “New Space” button. This will open up a form where you can configure your new Space.
- Step 4: Configure your Space.- Here, you’ll be able to choose a name for your Space, select its visibility (public or private), and choose the environment (CPU or GPU). You’ll also need to select the type of Space you want to create. For instance, if you’re planning to host a Gradio app, you should choose the “Gradio” option.
- Step 5: Deploy your Space.- After configuring your Space, click the “Create” button. This will create your new Space, and you’ll be able to see it listed on your Spaces page. Click on the Space to view more options.
You can write and deploy your Gradio app using the web editor available on the website. Also, an alternative is to code locally on your computer using any text editor and push the code into Hugginface. Once you’re ready, you can deploy your Space, which will be accessible via a unique URL.
For this project in particular, you’ll need to create an access token from your HugginFace account. You can find it under your profile, as you can see below.
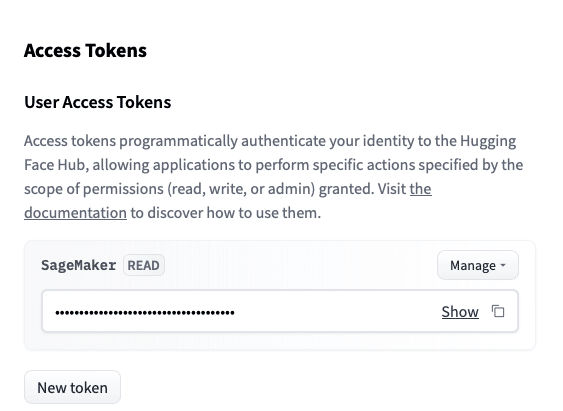
Then, you’ll need to configure the token as a secret for your Space in the settings tab. There you can define global variables as well.
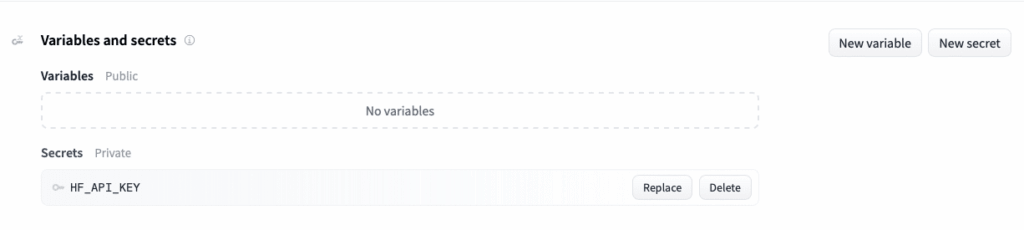
That’s it! You’ve successfully created and deployed a Space on Hugging Face. It’s an incredibly powerful platform that makes it easy to share your machine-learning models and applications with the world.
An Introduction to Gradio
In the vast ecosystem of AI tools, Gradio emerges as a game-changer, simplifying the process of building intuitive interfaces for machine learning models. At its core, Gradio is designed to make model experimentation and sharing more streamlined and user-friendly. With just a few lines of code, developers can swiftly transform their models into interactive web applications, allowing for real-time testing and feedback. This not only democratizes model accessibility but also enables rapid prototyping, fostering an environment where models can be iteratively improved based on immediate user interactions. From customizable input and output components to its compatibility with a wide array of frameworks, Gradio proves to be an indispensable tool for both novice and seasoned AI practitioners aiming to showcase their models to the world.
The magic of Gradio lies in its emphasis on real-time interactions. By providing an environment for immediate testing and feedback, developers are equipped with the tools to prototype and refine their models rapidly. This iterative approach accelerates the development cycle and fosters a culture of continuous improvement. Regardless of their technical expertise, users can engage with models, provide instantaneous feedback, and play an active role in shaping the model’s evolution.

Beyond its core functionality, Gradio impresses with its versatility. It boasts a range of customizable input and output components, ensuring that interfaces can be tailored to specific model requirements. Furthermore, its compatibility spans a broad spectrum of machine-learning frameworks. Thus, as the world of AI continues to expand, tools like Gradio are pivotal in ensuring that advancements in the field benefit all.
Deploying an AI Application: A Step-by-Step Guide
In this section, we walk you through creating a simple application that fetches responses from different AI models using their respective APIs. For that, you can check the current ranking of the LLMs available in HugginFace, which includes open-source and proprietary alternatives. It’s important to highlight that you must verify the Hardware requirements to avoid limitations.
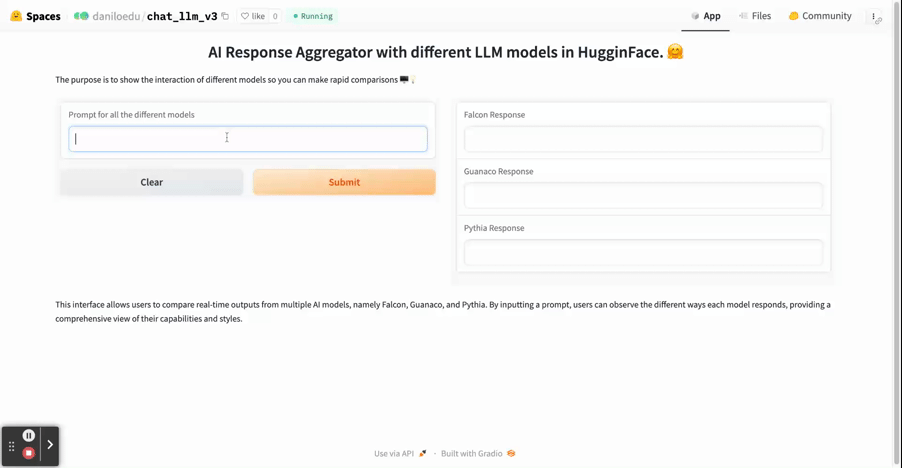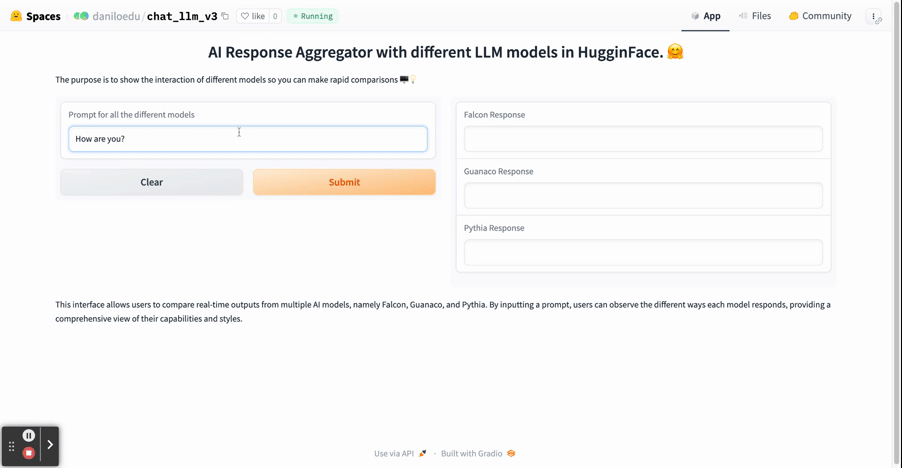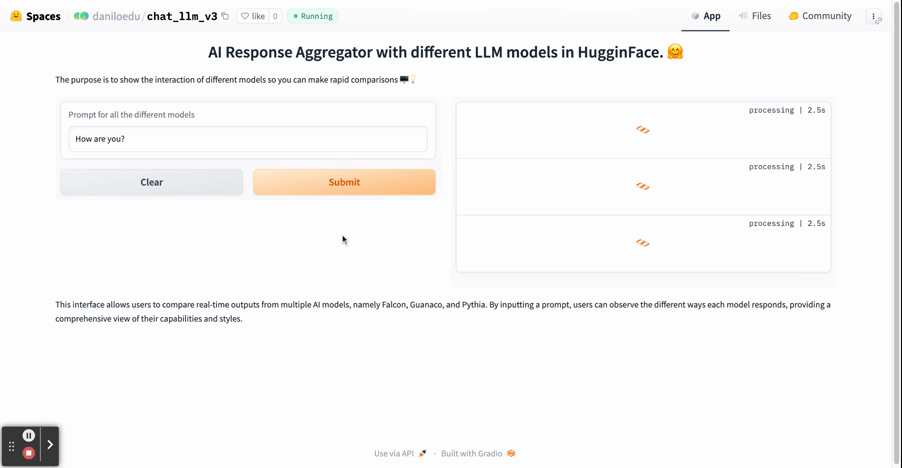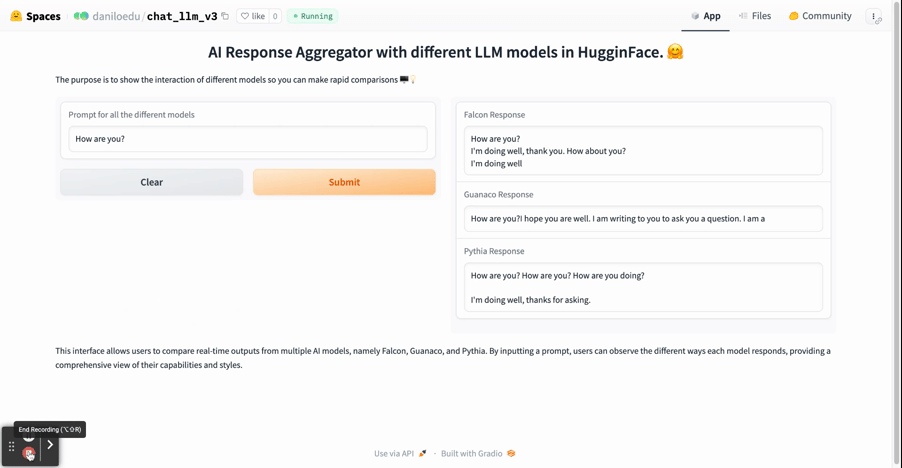
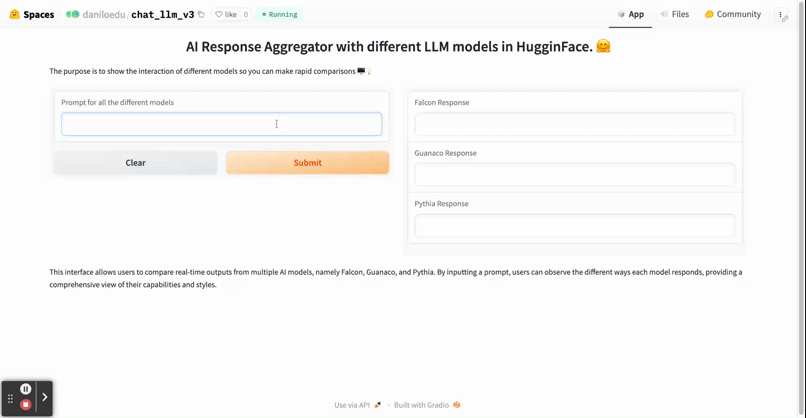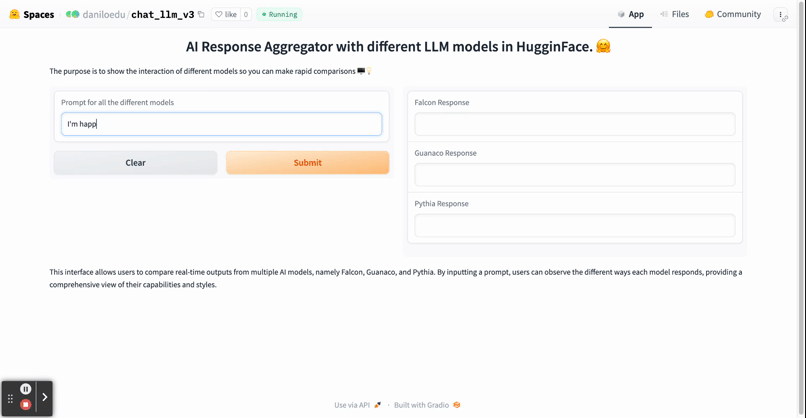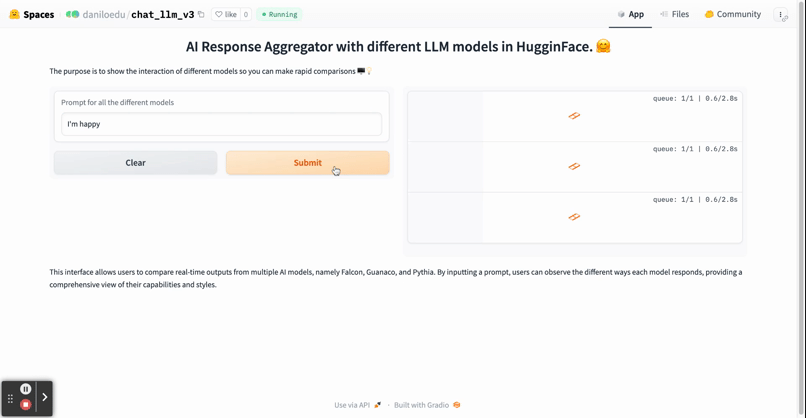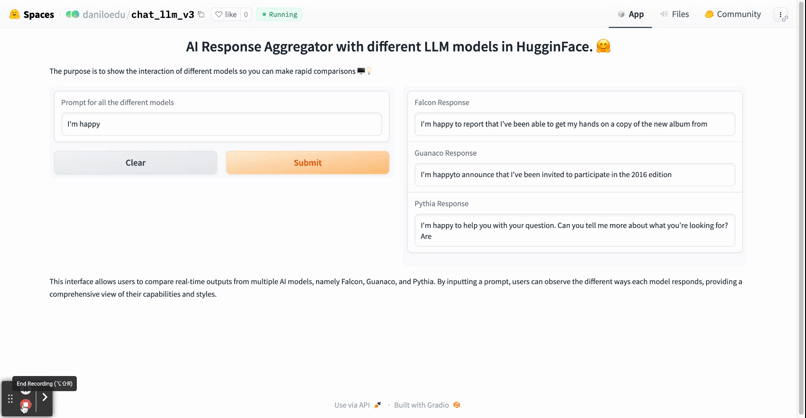
The main objective here is to compare how different AI models respond to the same user prompt. The AIs we use in our case study are Falcon, Guanaco, and Pythia. Find below a brief introduction of the models used.
Guanaco
Guanaco is a powerful text generation AI hosted on Hugging Face under the name timdettmers/guanaco-33b-merged. This model is designed to generate human-like text and is built on PyTorch and Transformers. It uses the Llama architecture, which is specifically designed for large language models. Guanaco’s name is inspired by the South American camelid, reflecting its resilience and ability to handle various tasks in the wild world of NLP.
Pythia
The OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5 model, more commonly known as Pythia, is part of the Open-Assistant project. This is the 4th iteration of their English-supervised fine-tuning model, and it is designed to handle conversational interactions. Pythia has been fine-tuned on human demonstrations of assistant conversations collected through the Open Assistant human feedback web app. The name Pythia draws from ancient Greek mythology, where Pythia was the high priestess of the Temple of Apollo at Delphi and served as the oracle who people consulted for divine advice and prophecies.
Falcon-7B-Instruct
The Falcon-7B-Instruct model, found under tiiuae/falcon-7b-instruct on Hugging Face, is a state-of-the-art model for chat and instruction tasks. This 7 billion parameter model is built by TII based on Falcon-7B and is fine-tuned on a mixture of chat and instruct datasets. One of Falcon-7B-Instruct’s unique features is its use of FlashAttention, an architecture optimized for inference. The Falcon-7B-Instruct model is an excellent choice if you’re looking for a ready-to-use model for generating conversational and instructive text. The name Falcon-7B-Instruct reflects its high speed and precision, much like the bird it’s named after.
The code to call different models.
In this section, we walk you through the process of creating a simple application that fetches responses from different AI models using their respective APIs. The main objective here is to compare how other AI models respond to the same user prompt. The AIs we use in our case study are Falcon, Guanaco, and Pythia.
Here’s a step-by-step explanation:
Step 1: Importing Necessary Libraries
The first step is to import the libraries we will use in our application. We need os to fetch environment variables, ‘requests' to make API calls and Gradio to create an easy-to-use and interactive UI for our application.
import os
import requests
import gradio as grStep 2: Setting Up API Details
We need the base URLs for the APIs of the AI models we are using. We also require an authorization token to make requests to these APIs. Here, we fetch the token from the environment variables for security purposes.
API_URLS = {
"falcon": "https://api-inference.huggingface.co/models/tiiuae/falcon-7b-instruct",
"guanaco": "https://api-inference.huggingface.co/models/timdettmers/guanaco-33b-merged",
"pythia": "https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5"
}
headers = {"Authorization": f"Bearer {os.getenv('HUGGINGFACE_TOKEN')}"}Step 3: Creating a Function to Query the APIs
Next, we define a function query that makes a POST request to a given API and returns the response.
def query(api_url, payload):
response = requests.post(api_url, headers=headers, json=payload)
return response.json()Step 4: Creating the Main Function
The respond function is the heart of our application. It takes a user’s message as input and returns the responses from all three AI models.
def respond(message):
responses = {}
for ai, api_url in API_URLS.items():
payload = {"inputs": message}
response = query(api_url, payload)
generated_text = response[0]['generated_text']
assistant_message = generated_text.split("Assistant:")[-1].strip()
responses[ai] = assistant_message
return responsesStep 5: Setting Up the User Interface
Finally, we use the Gradio library to create a simple and interactive user interface for our application.
iface = gr.Interface(
respond,
inputs=gr.inputs.Textbox(label="Input a message for the AI"),
outputs={
"falcon": gr.outputs.Textbox(label="Falcon Response"),
"guanaco": gr.outputs.Textbox(label="Guanaco Response"),
"pythia": gr.outputs.Textbox(label="Pythia Response")
},
)
iface.launch()With these steps, we have set up a simple web application where users can input a message and receive responses from three different AI models. This is a powerful way to compare the performance of different models and choose the one that suits your specific business needs the best.
You can check the deployed code at this link: https://huggingface.co/spaces/daniloedu/chat_llm_v3
Conclusion
The landscape of AI is ever-evolving, with tools and resources continually emerging to empower businesses in their quest for innovation. Today, even if a company might feel constrained by resources, platforms like HuggingFace or cloud-based solutions such as AWS Sagemaker stand ready to bridge the gap, enabling swift and efficient experimentation.
However, as we embrace the future, it’s paramount to remember that AI is not an island. Effective AI integration demands harmonization with existing processes and, crucially, with the people who drive our businesses. It’s not about replacing but enhancing. Thus, it’s about creating tools that augment human capabilities, bringing forth unprecedented efficiency and insights.
Moreover, while the allure of new and shiny AI models can be enticing, the real magic lies in judicious selection. It’s not about integrating just any model but the one that aligns seamlessly with a company’s ethos, objectives, and historical data. Consequently, the goal is to derive actionable insights, not just impressive metrics.
For businesses poised on the cusp of AI integration or those looking to refine their AI strategies, Origo stands as a beacon. Our mission is to guide and support companies in their AI journey, ensuring that they harness AI’s potential in ways that are meaningful, sustainable, and transformative. If you’re looking to embark on this exciting journey, know that at Origo, we’re not just equipped but eager to illuminate the path ahead.

For more information, contact us at info@origo.ec.